
Jeder hat das Gefühl, dass Wohneigentum in der Hauptstadt heutzutage teuer ist. Entschuldigung, sauteuer! Aber überall? Welche Rolle spielt denn die Lage? Im Data’n’Analysis-Team (kurz DNA) der Europace beschäftigen wir uns täglich mit solchen Fragen. Das Schöne ist, wir haben die Daten, wir haben die Formeln, und können so, schwuppdiwupp, die Kaufpreisunterschiede in den einzelnen Bezirken ermitteln. Also Stirnband um und los geht’s!
Wir fangen mal ganz locker an: Um herauszufinden, welche Bezirke besonders teuer sind, beschränken wir uns auf ein einfaches lineares Modell, das die Kaufpreise anhand der Wohnfläche und der Postleitzahl vorhersagt. Dies hat zwar den Nachteil, dass die Vorhersagen eine geringere Genauigkeit haben, aber dafür erhalten wir ein einfach interpretierbares Modell. Zunächst schauen wir uns aber die Datenlage genauer an.
Schritt für Schritt durch Daten waten
Zum Visualisieren der Postleitzahlenbezirke benutzen wir ShapeFiles. ShapeFiles beinhalten, einfach gesagt, die Form der einzelnen Postleitzahlenbezirke. Die hier benutzten ShapeFiles beinhalten alle Postleitzahlen in Deutschland, wir beschränken uns allerdings nur auf die in Berlin.
Um ein möglichst genaues Ergebnis zu erzielen, haben wir uns für eine etwas ausführlichere Herleitung entschieden: wir verwenden die bayessche Statistik nach dem Satz von Bayes.
Der Vorteil bei dieser Methode gegenüber klassischer Statistik ist, dass sie uns erlaubt, auch kleinere Datenmengen korrekt zu interpretieren. Das ist zwar etwas aufwendiger, aber das Ergebnis ist dafür stärker auf unsere Fragestellung zugespitzt und gibt uns so einen exakteren Einblick in die reelle Immobiliensituation.
Um etwas Schreibarbeit zu sparen, gruppieren wir bestimmte Postleitzahlen zu ihren Ortsteilen zusammen:

Dann filtern wir alle Immobilien heraus, die eine Wohnfläche kleiner oder gleich 0 haben und berechnen außerdem den Gesamtkaufpreis als Summe der Herstellungs- und Modernisierungskosten sowie des Kaufpreises und Grundstückkaufpreises (wenn jeweils vorhanden).


Die Immobilien wurden alle im Zeitraum 2016 bis jetzt zum Verkauf angeboten. Nicht unbedingt alle Immobilien wurden tatsächlich auch gekauft, da die Daten auch Anträge enthalten können, die von der Bank abgelehnt worden sind. Dies kann bedeuten, dass der Kauf nicht zustande kam. Es kann aber trotzdem davon ausgegangen werden, dass die Immobilien für denselben oder einen ähnlichen Preis verkauft wurden.

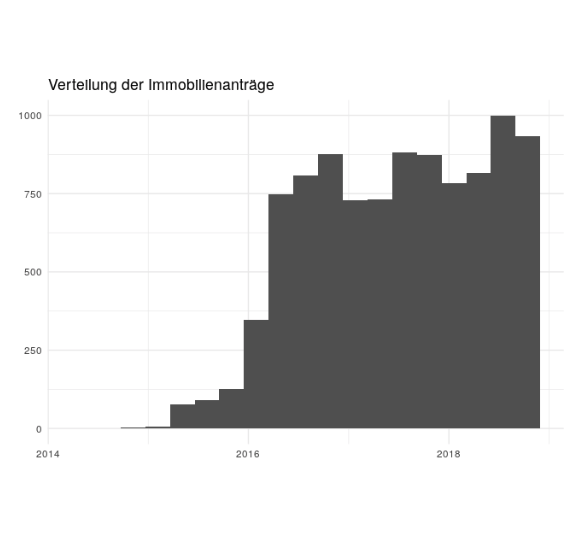
Was tun mit Daten-Ausreißern: Erst einfangen – dann aussetzen
Für eine lineare Regressionsanalyse sind insbesondere Ausreißer sehr problematisch. Wir werfen daher einen kurzen Blick auf die Verteilungen der Variablen:

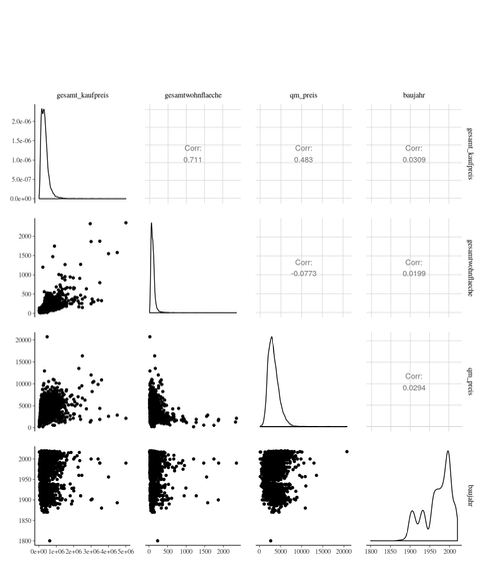
Und was hat Köpenick, was keiner hat: Eine 6.000.000 qm Wohnung
Sowohl Gesamtkaufpreis als auch Gesamtwohnfläche haben sehr rechts-schiefe Verteilungen. Keine Angst, das ist nicht politisches, es bedeutet nur, die Verteilungen haben lange Ausläufer nach rechts. Konkret bedeutet das, dass es ein paar Immobilien mit sehr hohem Kaufpreis beziehungsweise hoher Gesamtwohnfläche gibt. Für diese sehr hohen Werte gibt es zwei mögliche Erklärungen: Es kann sich um tatsächlich große, teure Häuser, wie zum Beispiel eine Villa in Dahlem handeln. Die andere Möglichkeit, und für unsere Auswertung sehr viel ungünstiger, sind Datenfehler, also falsch eingegebene Daten. Die Eigentumswohnung in Köpenick von einer Grundstücksgröße von 6 Millionen Quadratmetern scheint beispielsweise einer dieser Datenfehler zu sein. Nervig, aber es braucht mehr, als sechs Nullen, um einen Mathematiker aus der Ruhe zu bringen.
Dennoch, für ein lineares Modell können beide Ausreißer-Möglichkeiten schwierig sein. Einmal gibt es für diese Datenbereiche nur sehr wenig Daten und zweitens ist davon auszugehen, dass der Kaufpreis von Immobilien mit sehr großer Wohnfläche nicht mehr einem einfachen linearen Modell folgt. Es scheint beispielsweise sinnvoll anzunehmen, dass sehr große Objekte zu einem niedrigeren Quadratmeterpreis führen. Auch bei den Visualisierungen sind solche Ausreißer immer etwas problematisch, deswegen werde ich mich in dieser Analyse auf die eher „durchschnittlichen“ Immobilien konzentrieren.
Herausgenommen wurden daher Immobilien mit:
– Grundstücksgrößen größer als 5 000 Quadratmeter
– Gesamtwohnflächen größer als 500 Quadratmeter oder
– Gesamtkaufpreise größer als 3 Millionen €


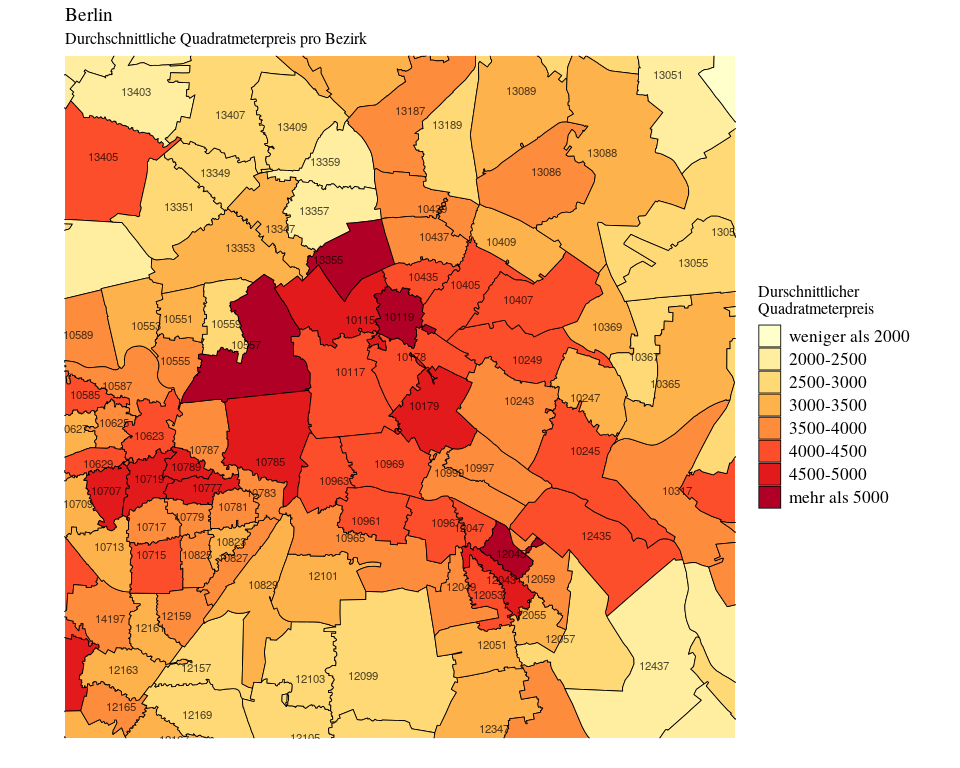
Und wo genau werden die meisten Objekte zum Kauf angeboten und für wieviel?
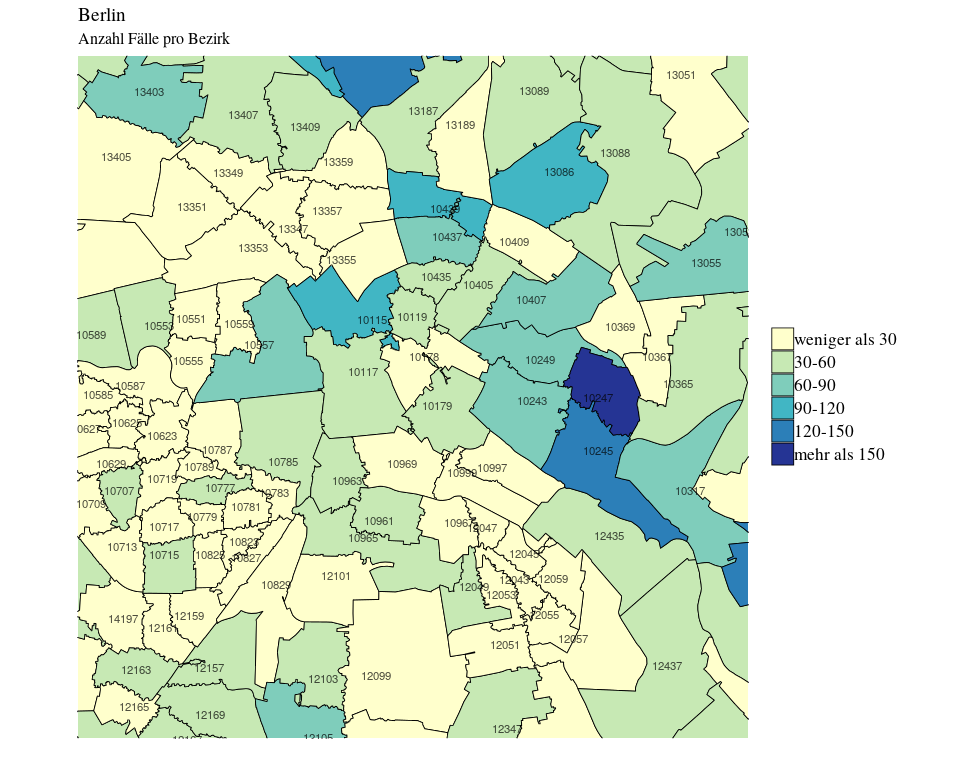
Nachdem wir nun die Daten noch einmal etwas eingrenzen konnte, interessiert uns natürlich jetzt, wie sich die übrigen, reellen Fälle an angebotenen Kaufobjekten über die Postleitzahlenbezirke hinweg verteilen.
Die meisten Postleitzahlbezirke haben etwa 30-40 Fälle von zum Verkauf angebotener Immobilien, nur Friedrichshain hat mit jeweils etwa 100 bis 200 Fällen sehr viel mehr.
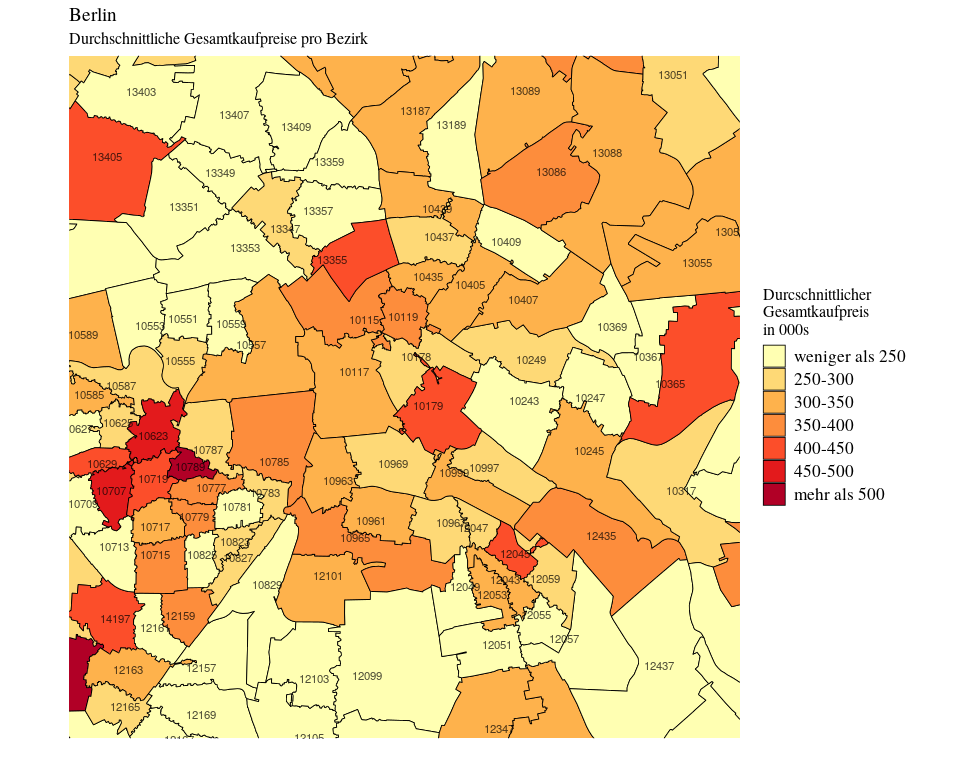
Und wie hoch ist der durchschnittliche Gesamtkaufpreis in den einzelnen Bezirken?
Ganz unten links auf der Karte kann man den Rand des Villenviertel Dahlem (PLZ 14195) sehen, mit Durchschnittspreisen von 664.000€. Die Gegend rund um das KaDeWe (PLZ 10789) ist mit durchschnittlichen Kaufpreisen von 772.000€ sogar noch etwas teurer.
Man muss hierbei bedenken, dass wir unter Umständen sehr kleine Eigentumswohnungen mit großen Villen vergleichen. Einen besseren Vergleich erhalten wir, wenn wir uns die durchschnittlichen Quadratmeterpreise anschauen.
Die teuersten Durchschnittsquadratmeterpreise sind in demnach Mitte-Tiergarten (10557) und – Trommelwirbel – im Wedding (13355) zu finden! Wedding hat allerdings weniger Fälle als der Durchschnitt, könnte daher also stärker verzerrt sein durch einzelne Fälle.
Wir wollen es aber noch genauer. Das Modell kann helfen
Da Postleitzahlen eine kategorische Variable mit sehr vielen Ausprägungen ist (in Berlin allein gibt es mehr als 100 Postleitzahlen), ist es oft sehr schwierig, diese sinnvoll in ein Modell zu integrieren. Um kategorische Variablen in einen numerischen Wert umzuwandeln, wird in Machine Learning häufig ein sogenanntes One-Hot Encoding genutzt. In einem One-Hot-Encoding wird für jeden Wert, den die kategorische Variable annehmen kann, eine Dummy-Variable erschaffen, die entweder 0 oder 1 ist. Ist eine Immobilie aus der Postleitzahl 10179, hätte die Dummy-Variable 10179 den Wert 1 und alle anderen Dummy-Variablen würden den Wert 0 annehmen. Das heißt, für jede Postleitzahl würden wir eine Variable hinzufügen. In unserem Datenset würde dies zu mehr als 100 zusätzlichen Variablen führen. Dies wird schnell rechenaufwändig und verschlechtert außerdem häufig die Modellqualität.
Zusätzlich ist davon auszugehen, dass sich der Quadratmeterpreis in den unterschiedlichen Bezirken stark unterscheidet. Das heißt also, dass die Variable Gesamtwohnfläche in den verschieden Postleitzahlbezirken einen anderen Einfluss auf den Kaufpreis hat. In Prenzlauer Berg würde beispielsweise ein Unterschied von einem Quadratmeter zu einer sehr viel stärkeren Änderung im Preis führen als in Lichtenberg. Eine Möglichkeit wäre hier, für jede Postleitzahl ein Modell zu berechnen. Dies ist ungünstig, da manche Bezirke sehr viel weniger Daten haben als andere und wir außerdem davon ausgehen müssen, dass der Einfluss der Gesamtwohnfläche in den einzelnen Postleitzahlbezirken zwar variiert, aber auch nicht zu stark. Wir würden erwarten, dass in Prenzlauer Berg der Einfluss der Gesamtwohnfläche höher ist als in Lichtenberg, aber in beide Postleitzahlbezirken hätte die Gesamtwohnfläche natürlich einen positiven Einfluss (größere Gesamtwohnfläche = höherer Preis).
Ausnahmsweise: Her mit dem hierarchischen Modell
Für solche Variablen eignet sich sehr gut ein hierarchisches Modell (die besonders gut mit den Bayesschen Methoden funktionieren). In einem hierarchischen Modell nehmen wir an, dass die Einflussfaktoren der einzelnen Postleitzahlen voneinander abhängen. Statistisch gesehen heißt das, dass die Einflussfaktoren (Koeffizienten genannt) von derselben Verteilung stammen. Prenzlauer Berg würde dann beispielsweise eher von den höheren Perzentilen der Verteilung stammen und Lichtenberg eher von den unteren.
Im Folgenden fitten wir ein solches hierarchisches Regressions-Modell, dass den Kaufpreis anhand der Wohnfläche per Postleitzahl vorhersagt. Die Formel dazu ist
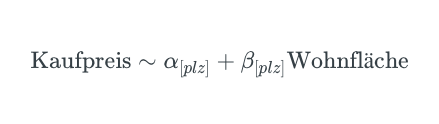
Wir nehmen also eine lineare Relation zwischen dem Kaufpreis und der Wohnfläche an. ![]() ist hier der
ist hier der ![]() Achsenabschnitt, im englischen Intercept genannt, und
Achsenabschnitt, im englischen Intercept genannt, und ![]() ist der Koeffizient, der den Einflussfaktor der Gesamtwohnfläche quantifiziert.
ist der Koeffizient, der den Einflussfaktor der Gesamtwohnfläche quantifiziert. ![]() gibt die Steigung des linearen Modells an. Für jede Postleitzahl wird ein
gibt die Steigung des linearen Modells an. Für jede Postleitzahl wird ein ![]() und ein
und ein ![]() berechnet.
berechnet.
Zum Berechnen benutzen wir das Package ![]() , welches ein sehr einfaches Interface für lineare Modelle bereitstellt. Als Backend wird die Modelling-Sprache Stan benutzt, aber
, welches ein sehr einfaches Interface für lineare Modelle bereitstellt. Als Backend wird die Modelling-Sprache Stan benutzt, aber ![]() erlaubt es uns, Bayessche Modelle in der gewohnten
erlaubt es uns, Bayessche Modelle in der gewohnten ![]() Formel Sprache von
Formel Sprache von ![]() zu spezifizieren.
zu spezifizieren.
Wir transformieren den Gesamtkaufpreis auf Kaufpreis in 100.000€, um so kleinere Koeffizienten zu erhalten. Für die Koeffizienten benutzten wir dann folgende Prior Verteilungen:

Da die Gesamtwohnfläche normalisiert und zentriert wurde, entspricht der Intercept ![]() dem Kaufpreis einer Immobilie mit durchschnittlicher Wohnfläche (~104m²). Ohne die Daten gesehen zu haben, würden wir erwarten, dass dieser Wert mindestens zwischen 100.000€ und 500.000€ liegt und haben daher den Prior Normal (3,1) gewählt. Mit einer ähnlichen Argumentation kommen wir zu dem Prior für den Steigungsparameter: Eine Änderung der Wohnfläche um etwa 50m² (eine Standardabweichung) sollte zu einer Preisänderung von etwa 50.000€ bis zu 150.000€ führen. Ein etwas weiterer Prior führte zu vergleichbaren Ergebnissen, das Modell scheint hier also recht stabil zu sein.
dem Kaufpreis einer Immobilie mit durchschnittlicher Wohnfläche (~104m²). Ohne die Daten gesehen zu haben, würden wir erwarten, dass dieser Wert mindestens zwischen 100.000€ und 500.000€ liegt und haben daher den Prior Normal (3,1) gewählt. Mit einer ähnlichen Argumentation kommen wir zu dem Prior für den Steigungsparameter: Eine Änderung der Wohnfläche um etwa 50m² (eine Standardabweichung) sollte zu einer Preisänderung von etwa 50.000€ bis zu 150.000€ führen. Ein etwas weiterer Prior führte zu vergleichbaren Ergebnissen, das Modell scheint hier also recht stabil zu sein.


Evaluation des Modells
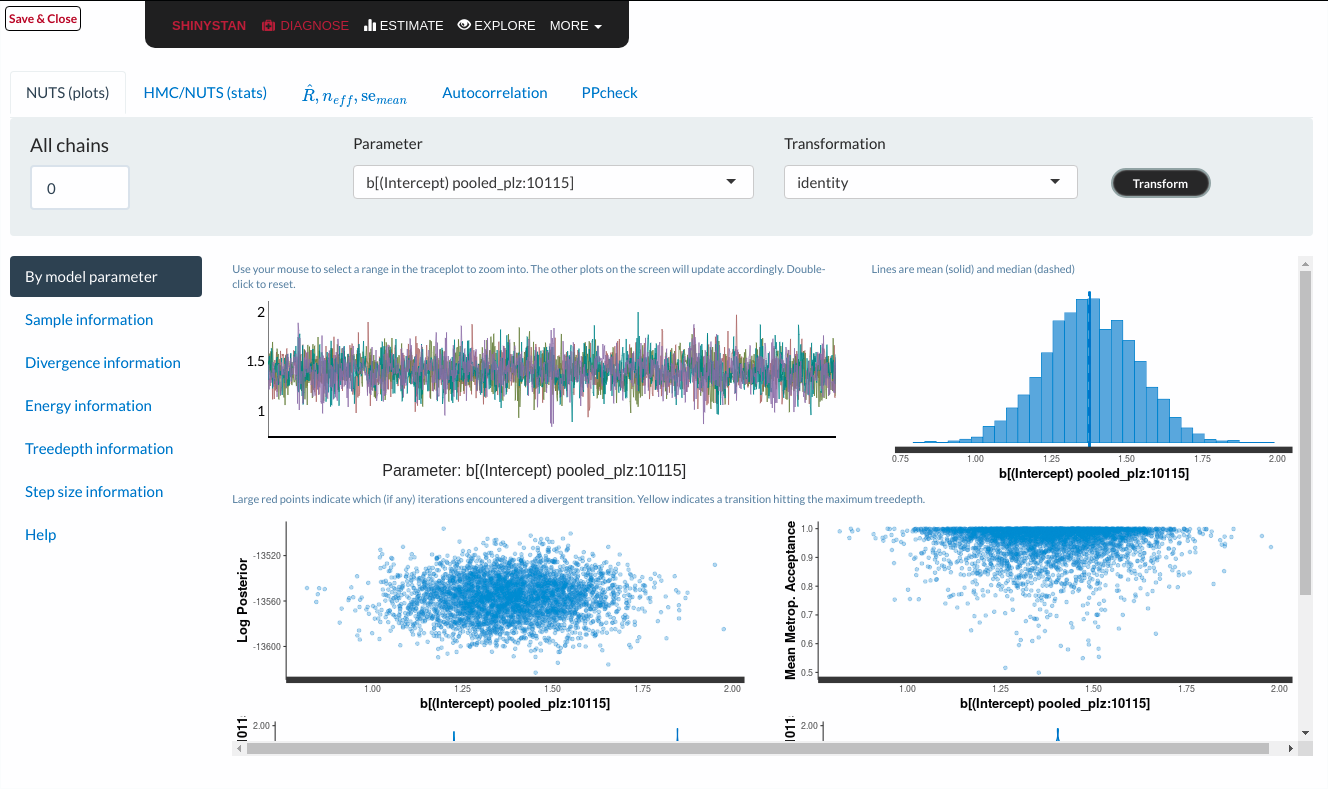
Das ![]() liefert mit
liefert mit ![]() eine einfache und praktische Möglichkeit, um zu überprüfen, ob das Modell konvergiert ist. Shinystan ist ähnlich wie Tensorboard nur für Bayessche Modelle. Anders als bei Tensorboard sehen wir zwar nicht das Live-Training, aber können das Modell nach dem fitten auf Herz und Nieren untersuchen. Zusätzlich zu Checks und Diagnostiken zur Konvergenz, gibt es auch Predictive Checks, die Einblicke geben, wie gut das Modell die echten Daten abbildet.
eine einfache und praktische Möglichkeit, um zu überprüfen, ob das Modell konvergiert ist. Shinystan ist ähnlich wie Tensorboard nur für Bayessche Modelle. Anders als bei Tensorboard sehen wir zwar nicht das Live-Training, aber können das Modell nach dem fitten auf Herz und Nieren untersuchen. Zusätzlich zu Checks und Diagnostiken zur Konvergenz, gibt es auch Predictive Checks, die Einblicke geben, wie gut das Modell die echten Daten abbildet.
{kind=link}

Was? Nur Bahnhof? Das macht nichts!
Wir werden jetzt nicht weiter auf die unterschiedlichen Diagnostiken und Checks eingehen, wichtig ist, dass in diesem Fall alle Modell-Diagnostiken gut aussehen und wir davon ausgehen können, dass unser Modell konvergiert ist. Erste Checks zur Qualität der Vorhersage sehen ebenfalls vielversprechend aus. Das schauen wir uns in den nächsten Plots genauer an.
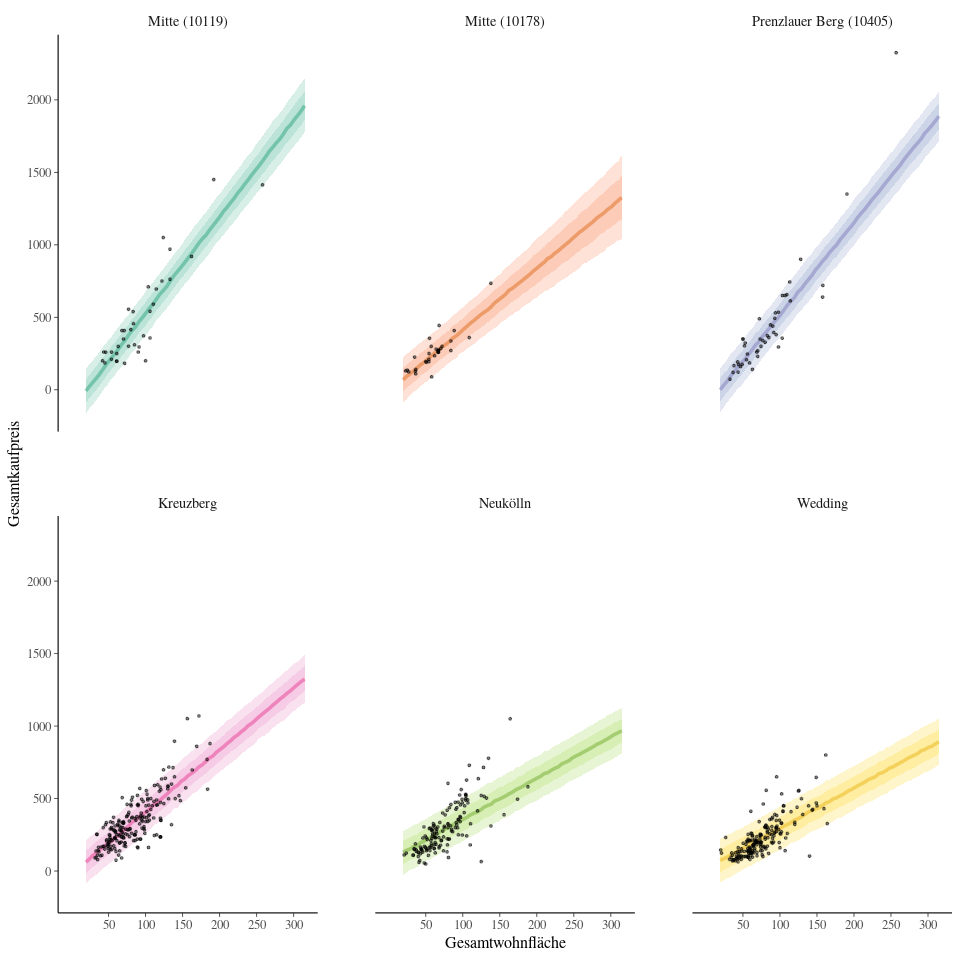
Da wir nicht alle Koeffizienten jeder Postleitzahl manuell untersuchen können, beschränken wir uns hier auf einige beispielhafte Postleitzahlen. Im Folgenden plotten wir die echten Fälle (in schwarz) über die Vorhersage (jeweils in Farbe). Die Credibility Intervals von 50% und 80% sind jeweils in leicht transparenten Farben geplottet. Eine gute Vorhersage würde also bedeuten, dass mindestens 80% der Punkte innerhalb des Farbringes sind.
Schick! Und was heißt das jetzt?
Per Augenmaß sehen die Vorhersagen erstmal ganz gut aus. Ein paar Dinge, die auffallen:
Im Modell haben wir die Postleitzahlen für Kreuzberg, Neukölln und Wedding jeweils zusammengefasst, da die Postleitzahlen in diesen Gegenden teilweise nur sehr wenige Daten hatten. Die unteren drei Graphiken basieren also auf den Daten von jeweils mehreren Postleitzahlen. Es scheint so, als ob dies auch zu einer größeren Preisvarianz in den zusammengefassten Daten führt.
In Neukölln gibt es außerdem zwei Immobilien mit mehr als 350m² Wohnfläche, deren Kaufpreis unter der Vorhersage liegt. Diese zwei Ausreißer führen dazu, dass die Steigung für Neukölln nach unten gedrückt wird. Da viele dieser sehr großen Immobilien Mehrfamilienhäuser sind, könnte das Modell hier verbessert werden, wenn man diese Variable (Objektart: Wohnung, Einfamilienhaus, Zweifamilienhaus, Mehrfamilienhaus) mit einbezieht.
Für Mitte (10119) sind die Vorhersagen auch für große Wohnflächen relativ gut und die hohe Steigung bestätigt, was man sich schon gedacht hat: Mitte ist teuer! Die Postleitzahl 10178, ebenfalls in Mitte, hat dagegen eine geringere Steigung, aber die breiteren Credibility Intervals zeigen auch eine größere Unsicherheit: Die meisten Immobilien dieser Postleitzahl sind mit weniger als 150m² relativ klein und dementsprechend ist die Unsicherheit hoch für größere Wohnflächen.
Der Intercept (weniger sexy auch der Grundpreis genannt) ist äquivalent zu dem Kaufpreis für eine durchschnittliche Immobilie (mit etwa 104m²). Diesen Wert können wir nun über alle Postleitzahlen hinweg vergleichen:
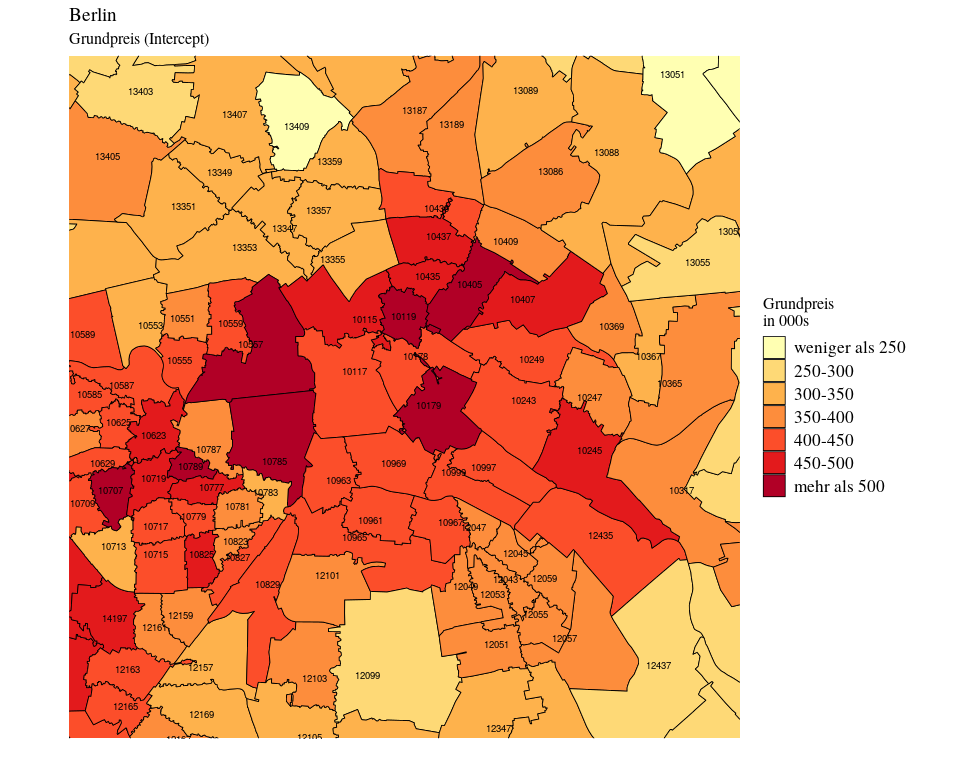
Dieser Grundpreis unterscheidet sich vom durchschnittlichen Kaufpreis insofern, als dass – sollte ein Bezirk überdurchschnittlich große oder eher kleine Wohnungen haben – der durchschnittliche Kaufpreis ebenfalls steigt oder sinkt.
Achtung, jetz‘ kütt et!
Während im Bild vorhin nur Dahlem mit seinen Villen und die Gegend um das KaDeWe als besonders teuer auffielen, sind in diesem Bild vor allem die Bezirke in Mitte und Prenzlauer Berg auffällig teuer. Während wir also vorhin große Villen mit kleinen Eigentumswohnungen verglichen haben, vergleichen wir hier, wie teuer dieselbe Wohnung in verschiedenen Bezirken wäre. Wir erhalten also den Preis für die Lage. Tadaaa!!!
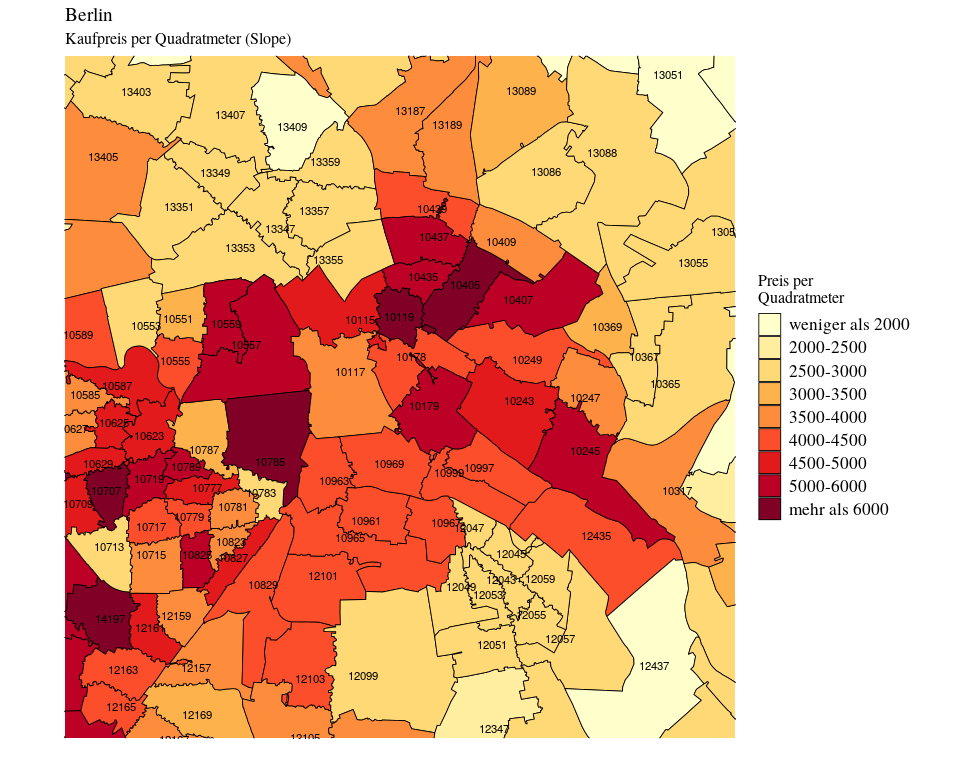
Die Steigung des Modells gibt an, wie viel teurer eine Immobilie wird, wenn sie einen Quadratmeter größer wird. Die Steigung ist also der Preis per Quadratmeter. Auch hier erhalten wir ein leicht anderes Bild als vorher, da wir nun den Preis der Lage durch den Intercept schon einberechnet haben.
Man beachte, dass Kreuzberg, Neukölln und Wedding zu jeweils mehreren Postleitzahlen zusammengefasst worden sind und daher über die Postleitzahlen hinweg die gleiche Estimates haben. Es darf außerdem nicht vergessen werden, dass unser Modell nicht gleich sicher ist für alle Postleitzahlen. Zum Beispiel in Mitte (10178) war sich unser Modell ziemlich unsicher, es kann also gut sein, dass sowohl der Grundpreis als auch der Preis per Quadratmeter höher ist als von unserem Modell angegeben.
Noch nicht ganz genau, wir rechnen nochmal weiter. Der R² des Modells liegt bei:

Das heißt, etwa 70% der Varianz des Kaufpreises wird durch unser Modell erklärt. Die Wohnfläche und Lage einer Immobilie bestimmen also fast vollkommen den Kaufpreis.
Wir haben oben schon gesehen, dass wir insbesondere große Immobilien im Preis häufig überschätzen. Im Folgenden analysieren wir, wie hoch die durchschnittliche prozentuale Abweichung des echten Kaufpreises zur Vorhersage ist. Wir benutzen hierzu den MAPE (mean average percentage error).
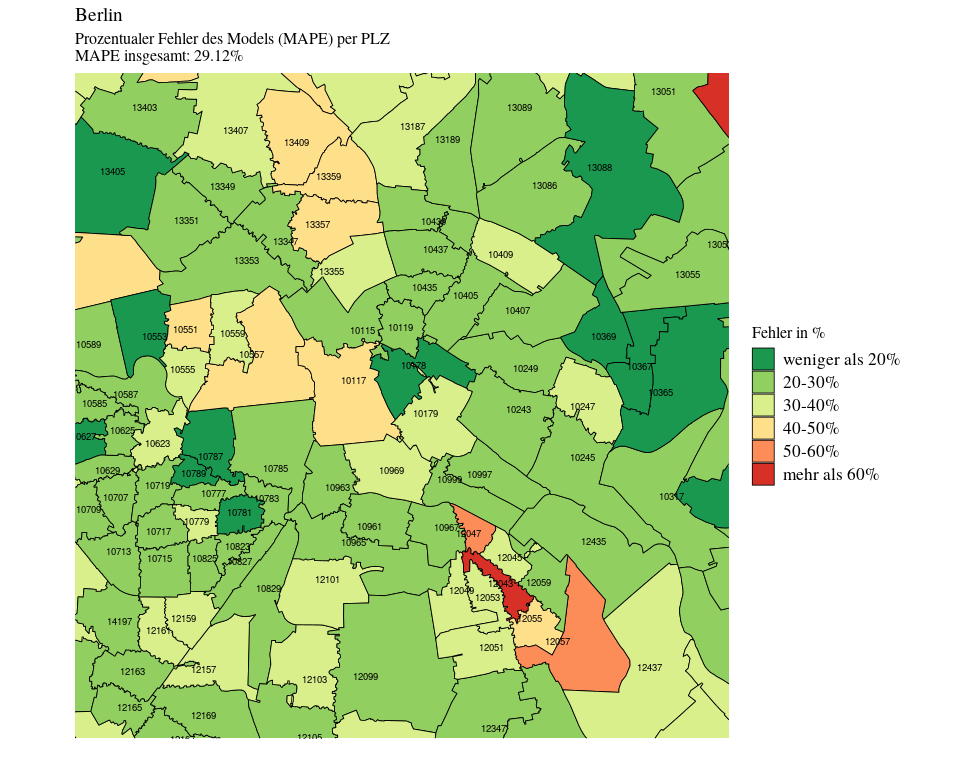
Insbesondere die Neuköllner Postleitzahlen haben eine hohe Fehlerquote. Es scheint, dass ein Pooling der Neuköllner Postleitzahlen das Modell hier eher verschlechtert hat. Andere Postleitzahlen, wie beispielsweise 10178 in Mitte, haben dagegen eine relativ geringe durchschnittliche prozentuale Fehlerquote von unter 20%.
Wie gut performt unser Modell verglichen mit einem Modell, in dem wir nur die Gesamtwohnfläche betrachten, also einem Modell, in dem wir die Lage vollkommen ignorieren?

Wieviel Varianz des Kaufpreises wird durch das alternative Modell erklärt?

Nur 52%!
Dies ist sehr viel schlechter als die 70% für das hierarchische Modell. Lage ist also ein wichtiger Faktor für den Preis einer Immobilie und sollte bei der Vorhersage von Kaufpreisen nicht ignoriert werden.
Für welche Bezirke performt das alternative Modell schlechter?
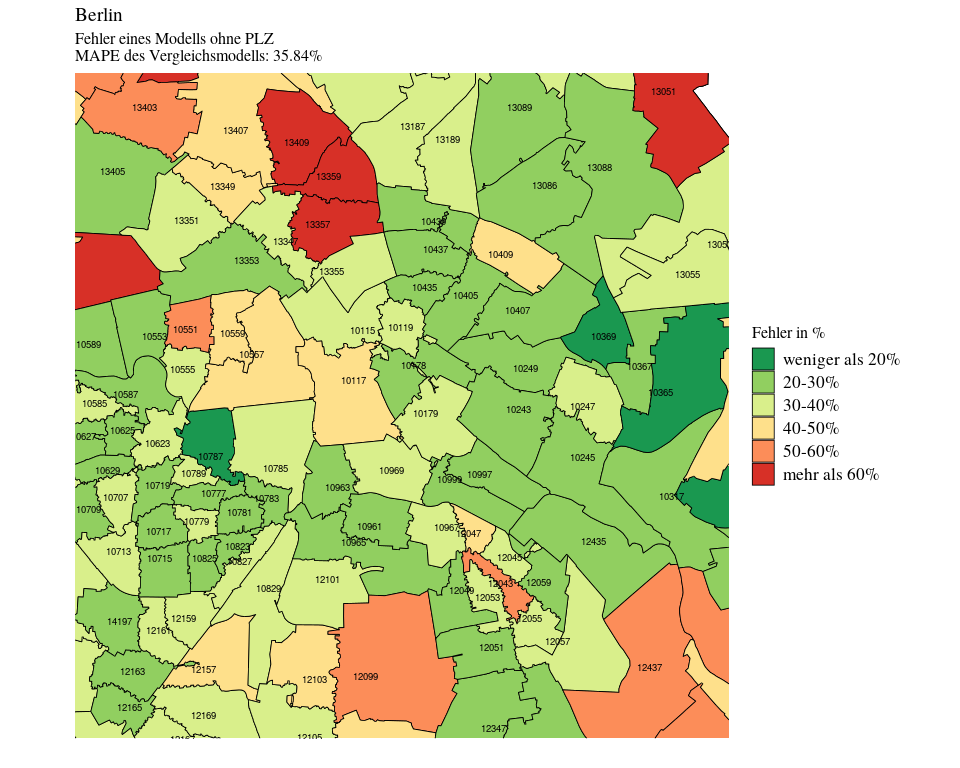
Verglichen mit dem hierarchischen Modell ist der Fehler des alternativen Modells sowohl insgesamt als auch für die einzelnen Postleitzahlen jeweils höher.
Interessanterweise performt das alternative Modell vor allem für umliegende Bezirke sehr viel schlechter. Das Modell überschätzt die Preise von Immobilien in günstigeren Lagen. Dies lässt sich erklären, wenn man sich erinnert, wie die Datenlage zur Verteilung der Immobilien in den Postleitzahlenbezirken war: Es gab sehr viele Daten über Immobilien in Friedrichshain und Prenzlauer Berg und eher wenig Daten zum Wedding, zu Kreuzberg, Neukölln und den Randbezirken. Friedrichshain und Prenzlauer Berg werden daher vom einfacheren Alternativ-Modell immer noch recht gut vorhergesagt, aber Bezirke wie der Wedding, die günstiger als Friedrichshain sind, schneiden dadurch im Modell schlechter ab.
Ein weiterer wichtiger Faktor, der in beiden Modellen nicht berücksichtigt wird, ist die Entwicklung der Preise über Zeit. Wir betrachten nur Immobilien der letzten zwei Jahre, aber in manchen Bezirken sind die Preise in dieser Zeit stark gestiegen. Es wäre spannend zu untersuchen, in welchen Bezirken die Preise stärker oder schwächer gestiegen sind.
Aber uns kreiselt jetzt der Helm, für heute haben wir genug gerechnet.